Obsah
- Jak najít slovo (nápověda)
- API
- O databázi
- O slovnících v databázi obsažených
- O projektu a členech řešitelského týmu
- Kontakt na autory ondrej.tichy@ff.cuni.cz
Jak najít slovo (nápověda)
Aplikace najdislovo.cz usnadňuje nalézání slov podobného významu. Když chcete například mluvit či psát o slunci, ale hledáte slovo pro daný účel vhodnější, můžete zadat do vyhledávacího okna "slunce" a zobrazit si hesla Vesmír > slunce v Tezauru jazyka českého (výsledky objevující se vlevo) nebo heslo Obloha a nebeská tělesa > Slunce v Českém slovníku věcném a synonymickém (výsledky objevující se vpravo). Dozvíte se tak, že o slunci můžete mluvit také jako o světlodárci nebo nebeském světlonoši (více o těchto slovnících v sekci O slovnících v databázi obsažených).
Obsah hesel obou slovníků se zobrazuje nezávisle: vlevo hesla z Tezauruu jazyka českého, vpravo hesla z Českého slovníku věcného a synonymického. Zobrazení nalezených hesel můžete měnit pomocí ikon zobrazených nad každým heslem:
- zobrazí/skryje heslář slovníku (sedm předcházejících a následujících hesel)
- zobrazí/skryje sken příslušné stránky tištěné verze Českého slovníku věcného a synonymického
- přepíná standardní a kompaktní zobrazení
- zobrazí/skryje významovou hierarchii hesel. Navigovat pomocí významové hierarchie můžete též kliknutím na některou z úrovní této struktury v záhlaví hesla (pod názvem slovníku). Takto můžete např. zobrazit hesla, která s právě zobrazeným heslem souvisí obecněji/volněji (např. další nebeská tělesa v případě slunce).
Když si nejste jisti, jak kýžený pojem vyhledat, můžete buď využít hierarchické významové struktury na vstupní stránce (kde slunce naleznete např. v části A. Vesmír. svět kolem nás > I. Obloha a zemské ovzduší > a. Obloha a nebeská tělesa > 8. Slunce), nebo použít další možnosti plnotextového vyhledávání.
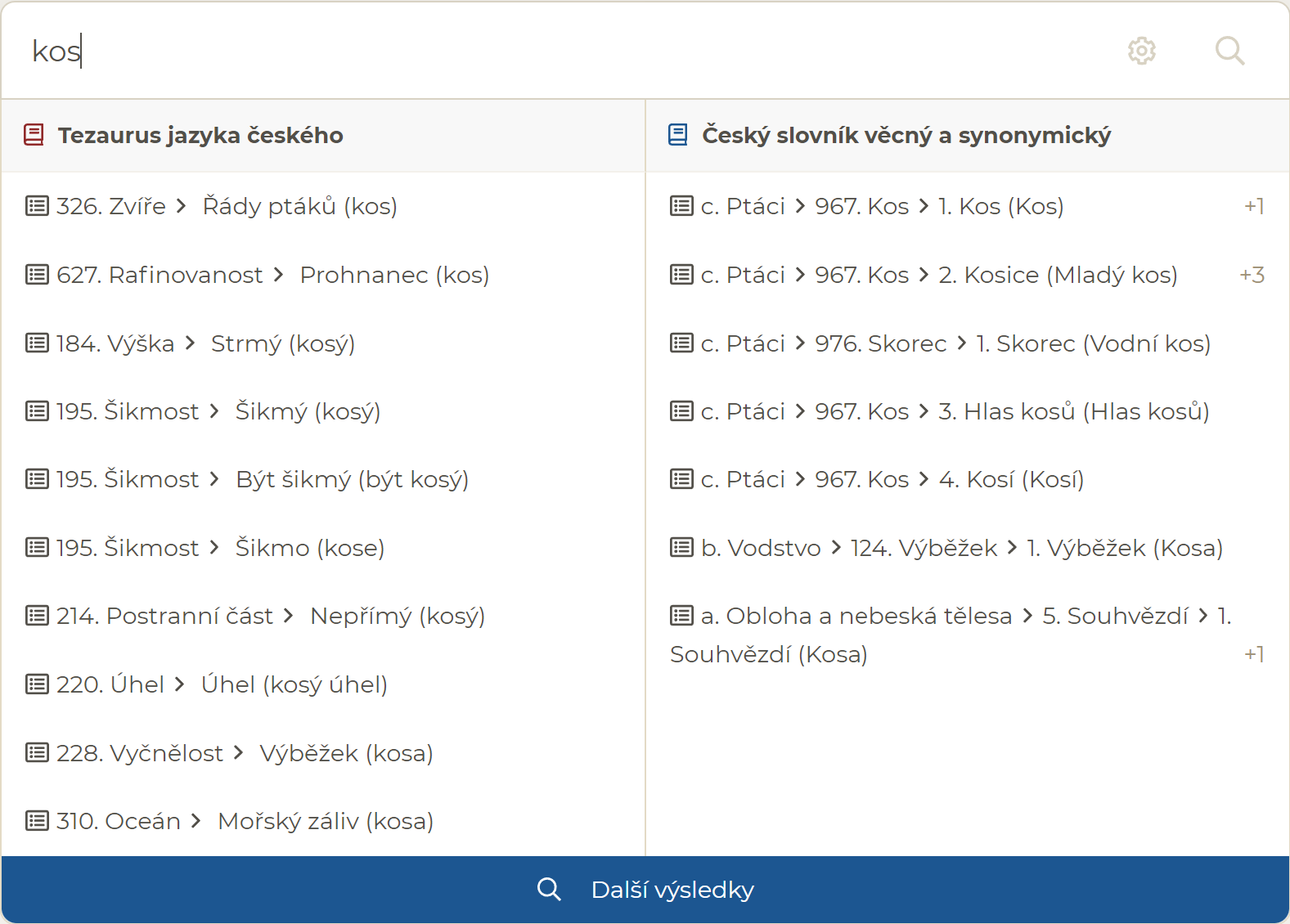
Základní vyhledávání nalezne hesla obsahující různé tvary zadaného slova. Pokud např. zadáte do vyhledávání "kos", naleznete nejen heslo kos, ale i třeba heslo kosa nebo kosice:
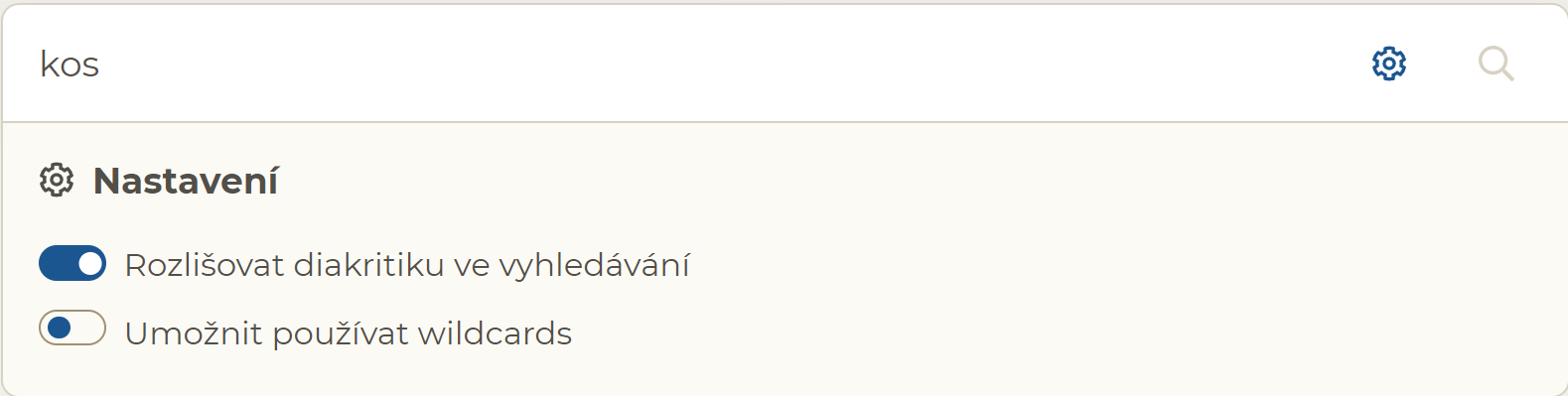
Pokud chcete vyhledávat formy bez ohledu na diakritiku (háčky a čárky) nebo přesněji určit tvary slov hledaného slova, klikněte na ikonu ozubeného kolečka v pravé části vyhledávacího okna:
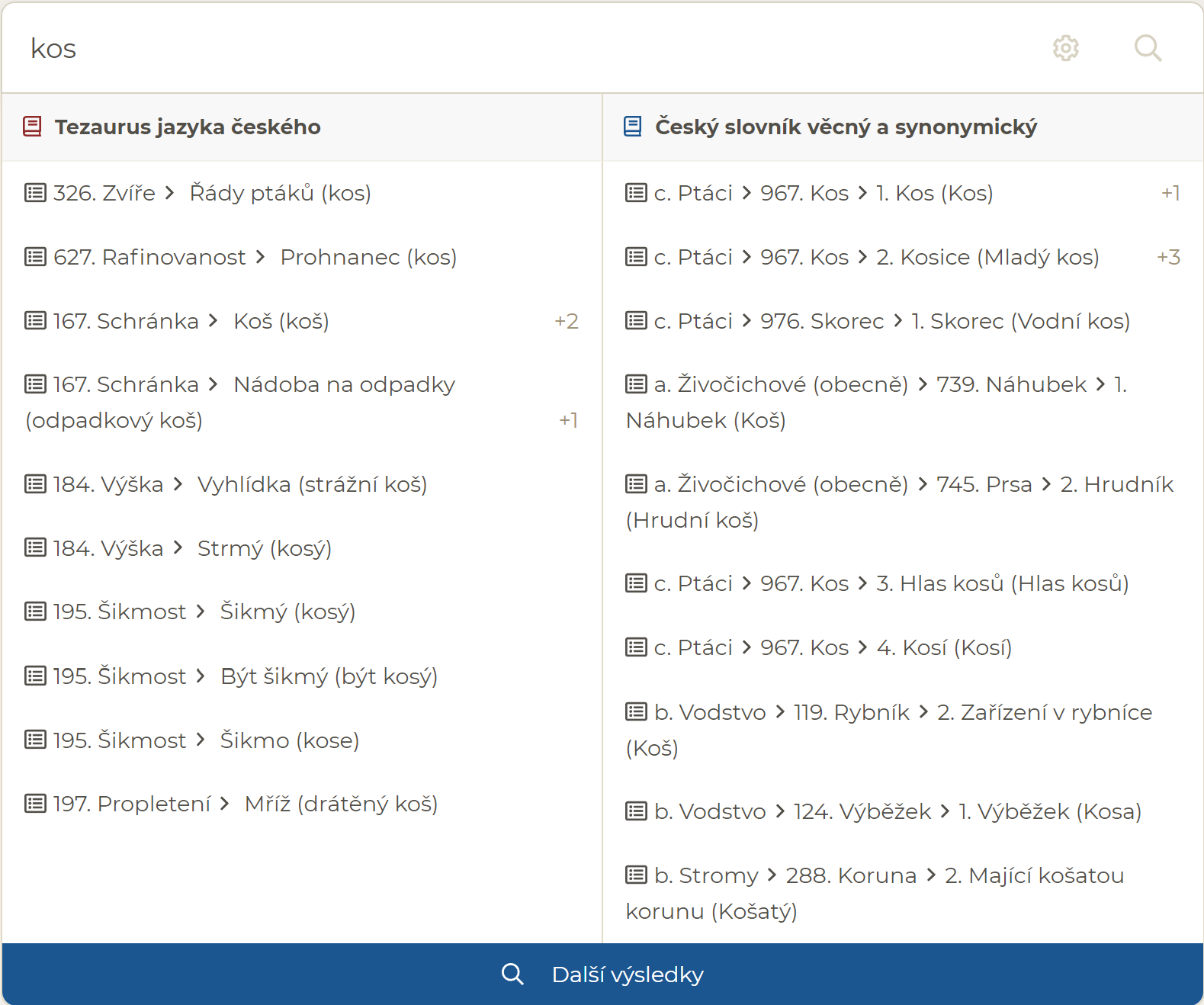
Pokud v nastavení vypnete rozlišování diakritiky ve vyhledávání, po zadání "kos" naleznete např. i heslo "koš":
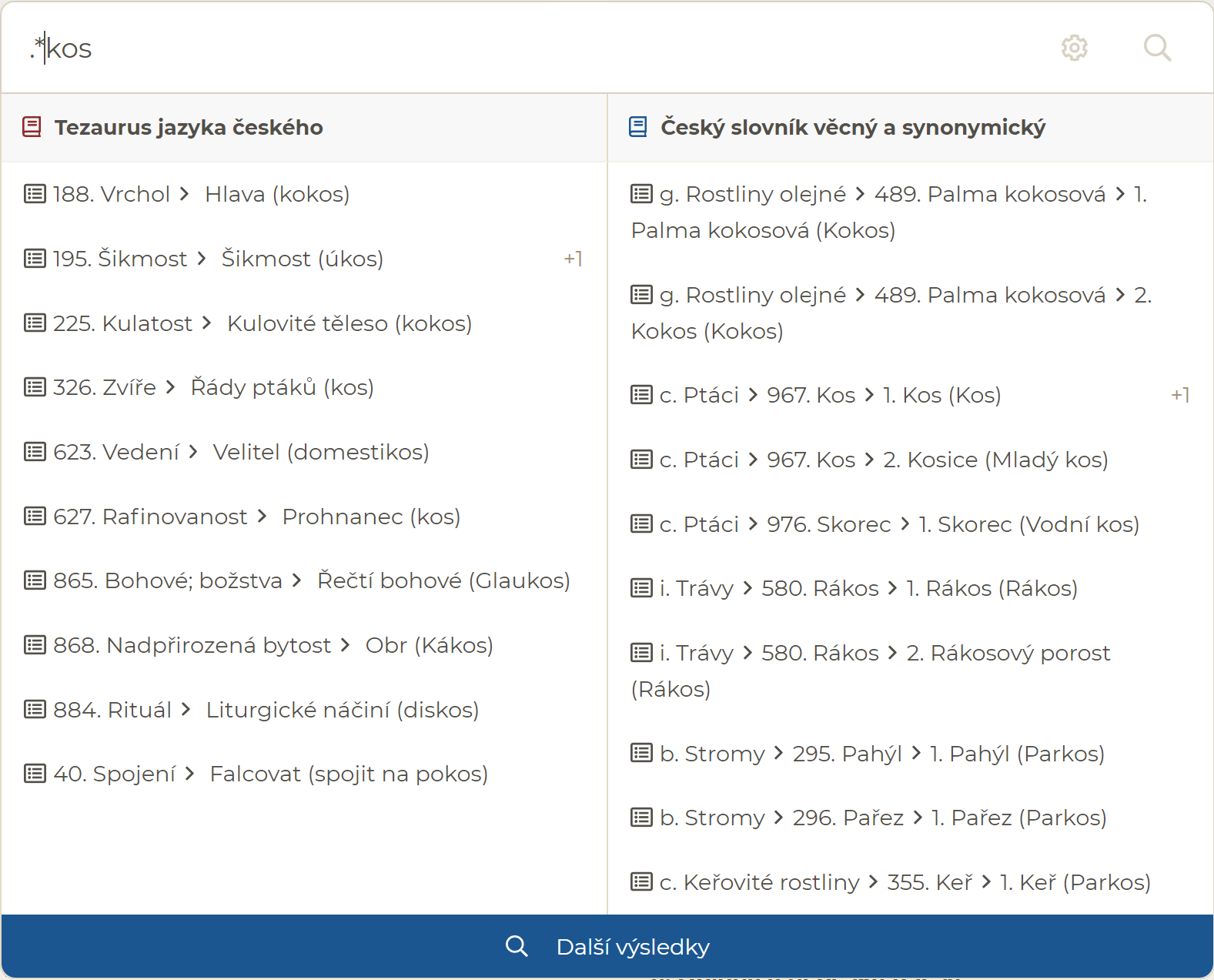
Pokud v nastavení umožníte používat tzv. wildcards (zástupné symboly), budou nalezena jen hesla obsahující tvary slov přesně odpovídající vyhledávanému textu a zadaným wildcars (definice použitých wildcards). Tedy vyhledáním kos naleznete pouze hesla obsahující kos, ale vyhledáním ".*kos" naleznete hesla končící na -kos jako kokos nebo *rákos":
Další výsledky vyhledávání zobrazíte kliknutím na ikonu lupy.
API
Databázi mohou dotazovat i aplikace třetích stran pomocí programového rozhraní (API).
Data projektu jsou dlouhodobě uchovávána (a průběžně aktualizována) v repozitáři LINDAT/CLARIAH-CZ.
O databázi
Lexikálně-sémantická databáze češtiny je založena na vytěžení lexika a struktur jediných dvou českých tištěných onomaziologických slovníků, Českého slovníku věcného a synonymického (Haller, 1969–86) a Tezauru jazyka českého (Klégr, 2007). Je určena dvěma skupinám uživatelů. Tou první je široká obec nelingvistů vytvářejících komunikáty v češtině, především překladatelů, spisovatelů, pracovníků médií či státní správy, ale i učitelů, studentů a veřejnosti. Druhou skupinu uživatelů tvoří lingvisté a další odborníci zabývající se výzkumem češtiny, korpusovou lingvistikou, zpracováním přirozeného jazyka, strojovým zpracováním textů a strojovým učením. Smyslem databáze je poskytnout těmto odborníkům datovou a strukturní základnu pro projekty sémantického značkování či strojového porozumění textu.
Onomaziologické slovníky napomáhají tvorbě kvalitních textů tím, že vedou uživatele od pojmu, významu k formě. Zpřístupnění těchto dvou českých tezaurů v digitální podobě vnímáme jako příležitost optimálně využít jejich obrovský výrazový potenciál: otevírají uživatelům nové cesty k lexikálnímu bohatství češtiny a nabízejí nové pohledy na české lexikum jako celek, jeho strukturu, členitost a provázanost. Zvláště v dnešní době velkých změn považujeme digitální přístup k oběma slovníkům za důležitý faktor pro zachování mezigenerační kontinuity české slovní zásoby. Do budoucna počítáme i s průběžnou aktualizací databáze, která tak umožní nejen uchovat výsledky celých desetiletí práce českých lexikografů, ale také je dále zhodnocovat.
O slovnících v databázi obsažených
Pojmové slovníky (označované také jako tematické, věcné či ideologické) patří do kategorie tzv. onomaziologických slovníků. Tyto slovníky třídí lexikální jednotky (slova, fráze, idiomy) nikoli podle jejich formy, jak to činí slovníky abecední, nýbrž podle jejich významu, pojmového obsahu. Zatímco abecedně uspořádané, výkladové (sémaziologické) slovníky mají za cíl přiřadit slovům (formám) odpovídající význam, smyslem onomaziologických slovníků je ukázat, jakými slovy lze ten který význam (pojem) vyjádřit, pojmenovat.
Pojmové slovníky vyšly v češtině dva, což je u tak „malého“ jazyka poměrně výjimečný jev; čeština se tím staví na roveň nevelkému počtu jazyků, které mají své vlastní tezaury. První ze slovníků, na kterém je databáze založena, je Český slovník věcný a synonymický (Haller, 1969–1986), uspořádaný podle osnovy Rudolfa Halliga a Waltera von Wartburga (Begriffssystem als Grundlage für die Lexikographie, 2. vydání z roku 1963). Má složitou hierarchickou strukturu, od nejvyšší úrovně až po samotná hesla, a encyklopedický charakter přesahující rámec čistě jazykového slovníku. Tři svazky, publikované v letech 1969, 1974 a 1977, obsahují na nejvyšší úrovni hierarchie tyto oddíly: A. Vesmír, svět kolem nás; B. I. Člověk, bytost tělesná a B. II. Duševní stránka člověka. Jak bývá u pojmových slovníků zvykem, byl pro snadnější vyhledávání doplněn abecedním rejstříkem (1986). Třebaže po smrti Jiřího Hallera zůstalo dílo nedokončeno, obsahuje úctyhodné množství lexikálního materiálu: na 1594 stranách je do 3193 hesel s proměnlivou vnitřní stavbou (mikrostrukturou) seřazeno přes 400 000 jednoslovných i víceslovných lexikálních jednotek. Obsažené výrazy jsou doplněny typickými spojeními (kolokacemi), příkladovými větami, někdy jsou opatřeny i definicemi a stylisticky charakterizovány pomocí široké palety zkratek a značek.
Východiskem pro druhý slovník, Tezaurus jazyka českého. Slovník českých slov a frází souznačných, blízkých a příbuzných (Klégr, 2007) bylo dílo publikované před 170 lety v Anglii, Thesaurus of English Words and Phrases (Roget, 1852). Dlouhá historie anglického tezauru, po celou dobu průběžně revidovaného, doplňovaného a aktualizovaného, prokázala užitečnost jeho koncepce a nesmírnou oblibu u uživatelů. Do současnosti se prodalo přes 32 milionů výtisků a z britské linie se později oddělily v nejrůznějších podobách americká a následně i australská verze. Tezaurus jazyka českého (TJČ), který vychází ze zkráceného anglického vydání (Carney & Waite, 1985), obsahuje cca 250 000 forem (lexií) a implicitně zachovává Rogetovu makrostrukturu, a tedy hierarchii, výběr a uspořádání hesel, včetně kontrastního řazení hesel jdoucích za sebou (začátek, konec; síla, slabost). V TJČ jsou však explicitně vyznačeny pouze nejvyšší a nejnižší rovina této hierarchie: abstraktní třídy (I. Abstraktní vztahy, II. Prostor, III. Hmota, IV. Intelekt: užívání mysli, V. Volní oblast – uplatnění vůle, VI. Emoce) a samotné pojmy, tj. vlastní hesla (1–885). Stavba hesel je na rozdíl od Hallerova slovníku pevná a spočívá v rozdělení slov spojených s daným pojmem na substantiva, adjektiva, slovesa a příslovce (příslovečná určení). Jednotlivé slovní druhy jsou dále členěny na významové podskupiny (např. vlastnost, činnost, nositel vlastnosti, agens, patiens spojené s daným pojmem apod.), které tvoří lexikální pole (synonym, meronym a (ko)hyponym). Hesla jsou rovněž opatřena odkazy na hesla jiná. Součástí tištěného slovníku je opět abecední rejstřík usnadňující vyhledávání.
Přestože jsou oba slovníky míněny v zásadě jako stylistické příručky umožňující přesné a bohaté vyjadřování, liší se nejen dobou svého vzniku, ale také strukturou, zpracováním a zaměřením (Český slovník věcný a synonymický má spíše encyklopedický charakter, Tezaurus jazyka českého má blíže ke slovníku synonym), a překrývají se tak jen částečně.
Úvod a zkratky Českého slovníku věcného a synonymického
O projektu a členech řešitelského týmu
Současný stav projektu
V aplikaci najdiSlovo.cz nyní na Ústavu anglického jazyka a didaktiky a Ústavu románských studií Filozofické fakulty Univerzity Karlovy dále rozvíjíme projekt Lexikální sémantické databáze češtiny.
Do aplikace postupně přidáváme funkce vyžádané uživateli a průběžně opravujeme slovníková data. Některé části ČSVS tak nemusejí být dočasně dostupné v plnotextové podobě, jsou ale dohledatelné a je možné zobrazit sken příslušné stránky tištěného slovníku.
Budeme vděčni za zpětnou vazbu uživatelů aplikace a to nejlépe emailem na adresu: ondrej.tichy@ff.cuni.cz.
Projekt LSD-CZ TAČR
Projekt Lexikální sémantické databáze češtiny TAČR (ÉTA) TL02000041, na jehož realizaci se pod vedením Aleše Klégra podílela dvě pracoviště, Filozofická fakulta Univerzity Karlovy a Ústav pro jazyk český AV ČR, byl řešen v letech 2019–2022. Spolupracovali na něm tito členové řešitelského týmu:
Filozofická fakulta UK
- prof. PhDr. Aleš Klégr (hlavní řešitel, autor TJČ, lingvista)
- Mgr. Ondřej Tichý, Ph.D.(odborná koordinace, lingvista)
- PhDr. Zora Obstová, Ph.D. (administrativní koordinace, lingvistka)
- Mgr. Martin Roček (technická koordinace, programátor, grafik)
- Mgr. Kateřina Vašků, Ph.D. (lingvistka)
Ústav pro jazyk český AV ČR
- Mgr. Michaela Lišková, Ph.D. (lingvistka)
- Mgr. Jan Křivan, Ph.D. (lingvista)
korektorky a korektoři z řad studentek a studentů FF UK
Aplikačními garanty projektu, zastupujících významné skupiny budoucích uživatelů databáze, byly v abecedním pořadí:
- Česká asociace pro digitální humanitní vědy, z. s.
- Jednota tlumočníků a překladatelů
- Obec překladatelů
- Sjednocená organizace nevidomých a slabozrakých České republiky, z. s.
- Ústav formální a aplikované lingvistiky MFF UK
Poděkování
Databáze vznikla díky podpoře České technologické agentury v rámci programu ÉTA [TL02000041]. Za poskytnutí autorských práv k Českému slovníku věcnému a synonymickému děkujeme dědičce Jiřího Hallera Jitce Vitoušové a za poskytnutí práv k Tezauru jazyka českého jeho autorovi Aleši Klégrovi a Nakladatelství Lidové noviny, které tištěnou verzi vydalo.
Podrobnější informace o databázi:
Literatura:
Carney, F. & Waite, M. (eds) (1986). Pocket English Thesaurus. London: Penguin.
Haller, J. (1969–86). Český slovník věcný a synonymický 1–3, Rejstřík. Praha: Státní pedagogické nakladatelství.
Hallig, R. & Wartburg, W. von (1963/1952). Begriffssystem als Grundlage für die Lexikographie. Versuch eines Ordnungsschemas. Berlin: Akademie-Verlag.
Klégr, A. (2007). Tezaurus jazyka českého. Slovník českých slov a frází souznačných, blízkých a příbuzných. Praha: Nakladatelství Lidové noviny.
Roget, P. M. (1852). Thesaurus of English Words and Phrases Classified and Arranged so as to Facilitate the Expression of Ideas and Assist in Literary Composition. London: Longman, Brown, Green, and Longmans [new editions 1879 (ed. J. L. Roget), 1925, 1936 (ed. S. Romilly Roget)].
Kontakt
Kontakt na autory: ondrej.tichy@ff.cuni.cz. Zpětnou vazbu včetně námětů k vylepšení a hlášení chyb je možné vkládat přímo na GitHubu.